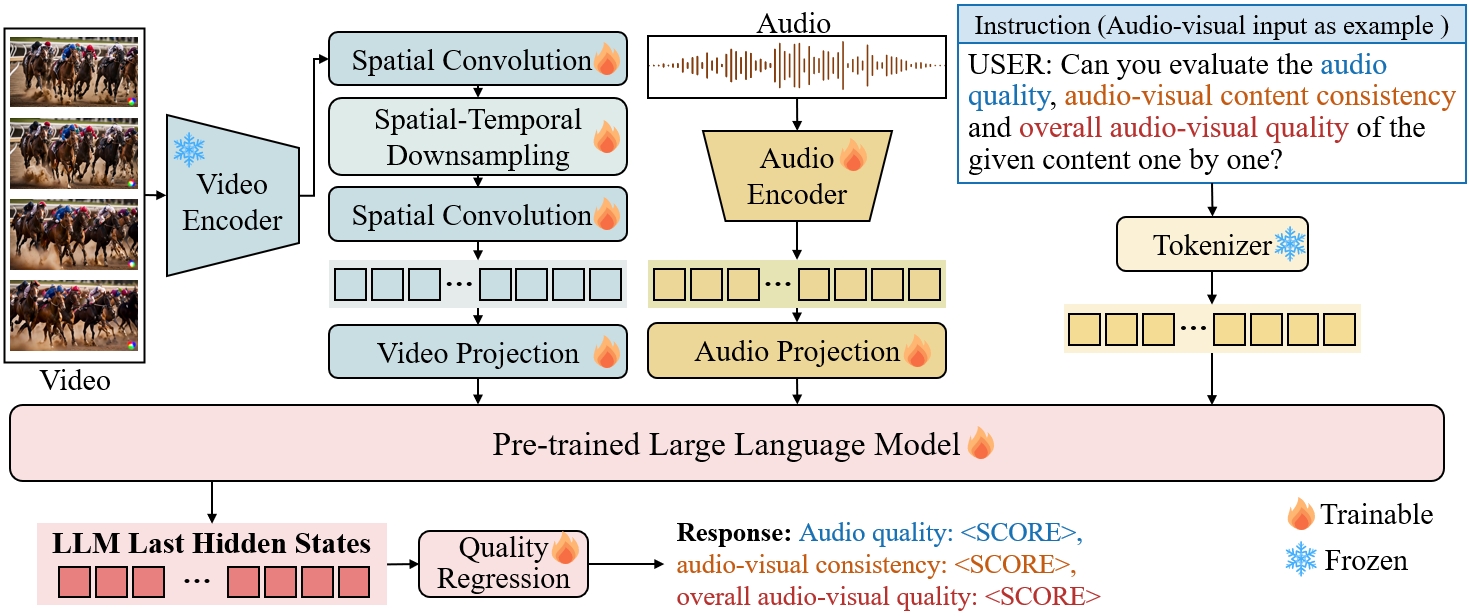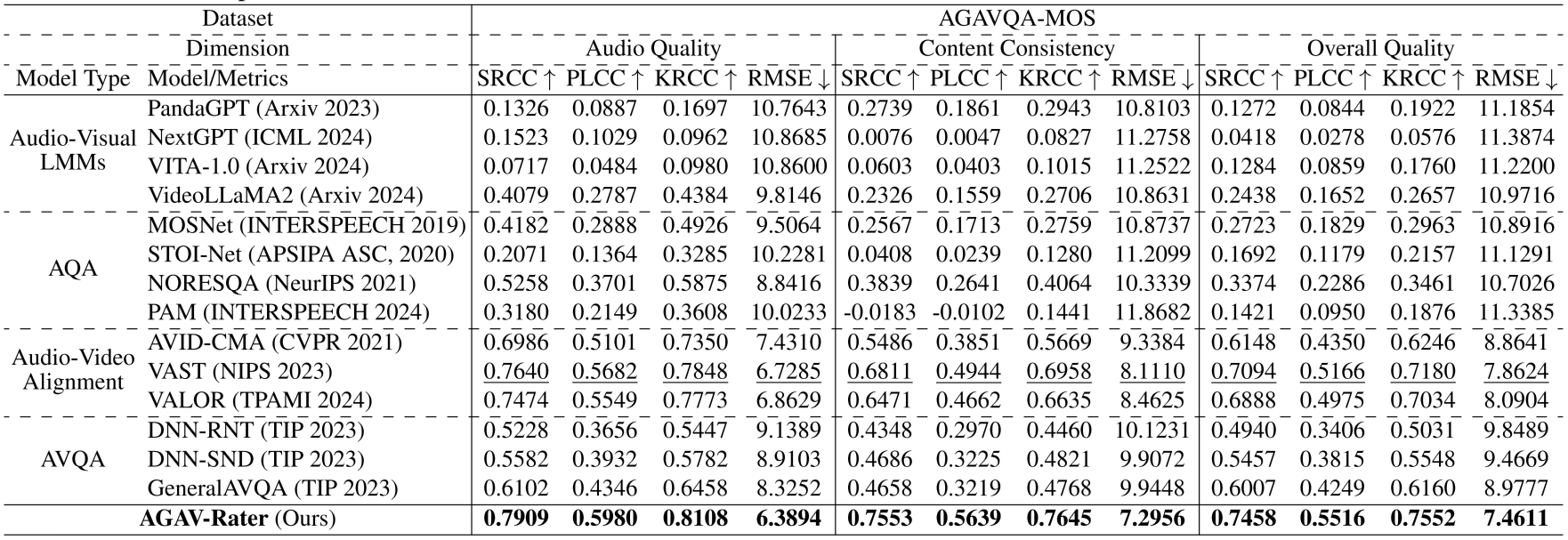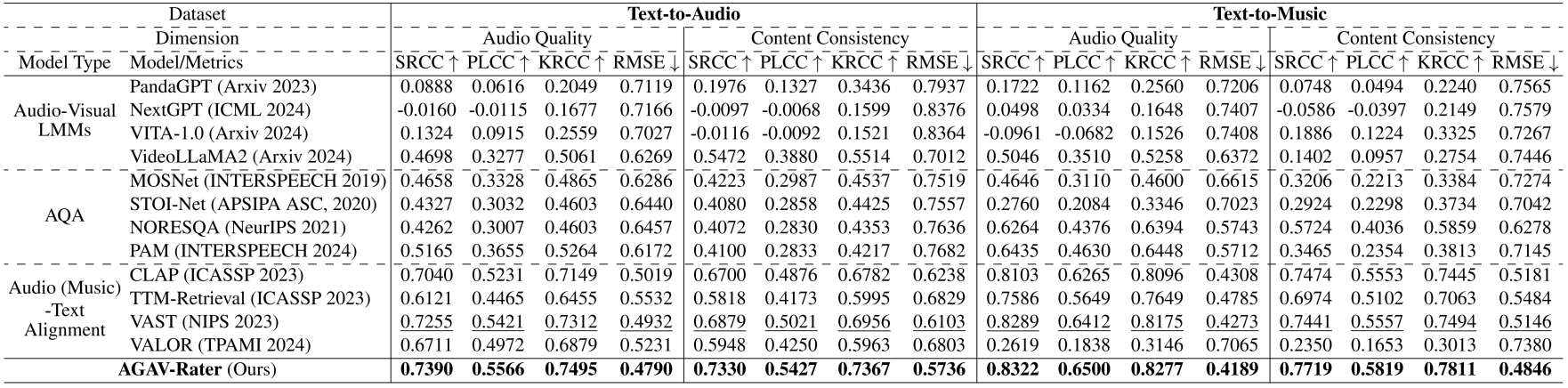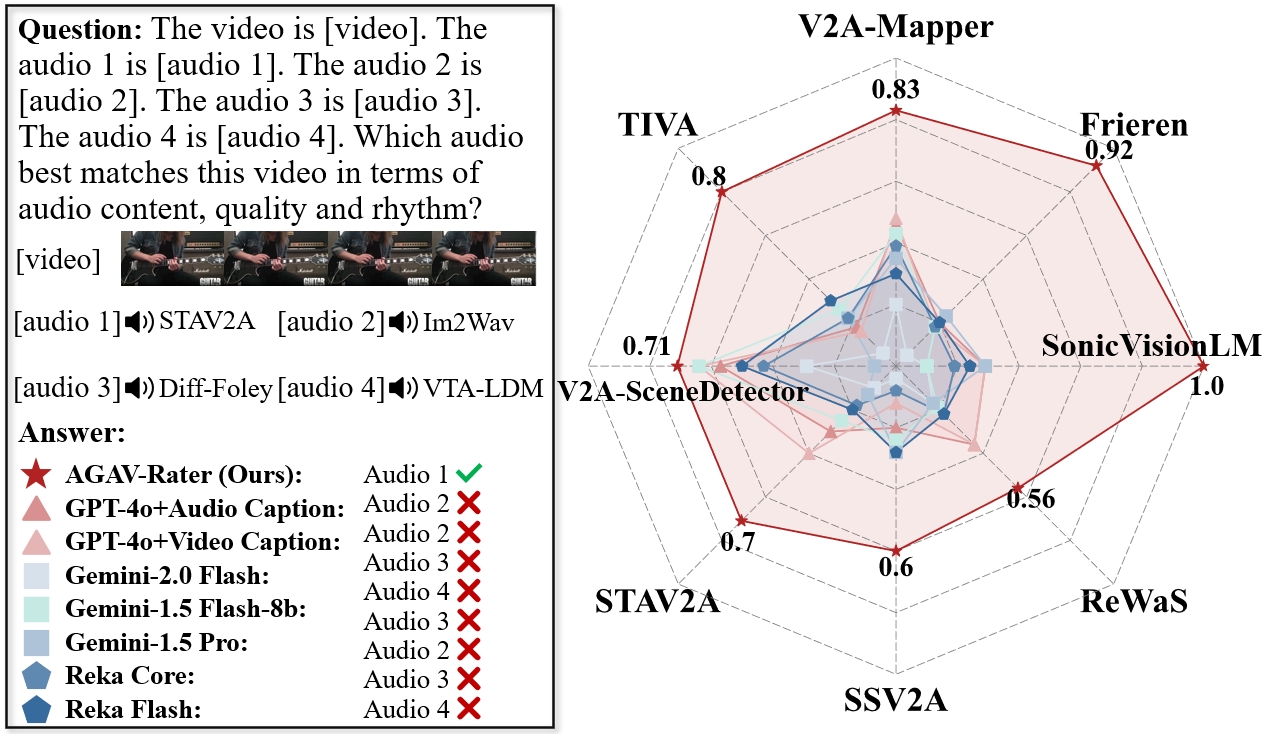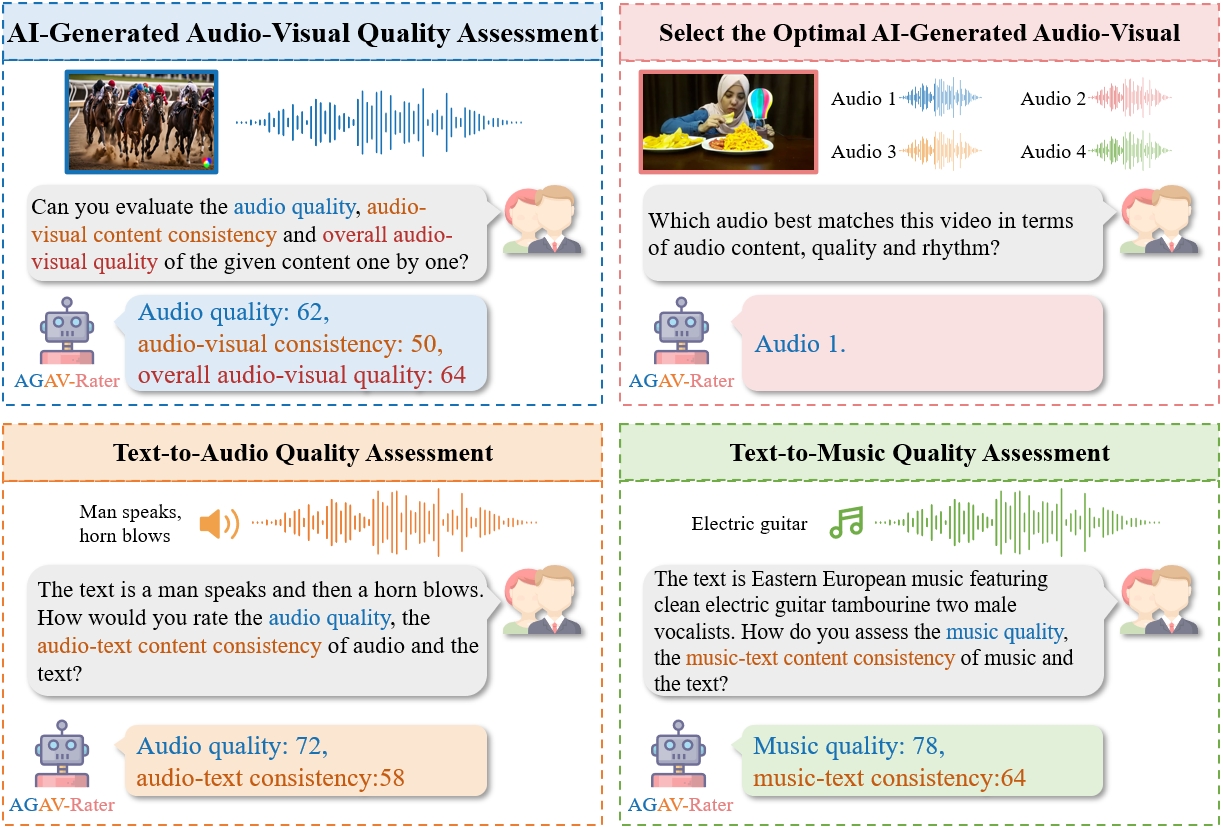

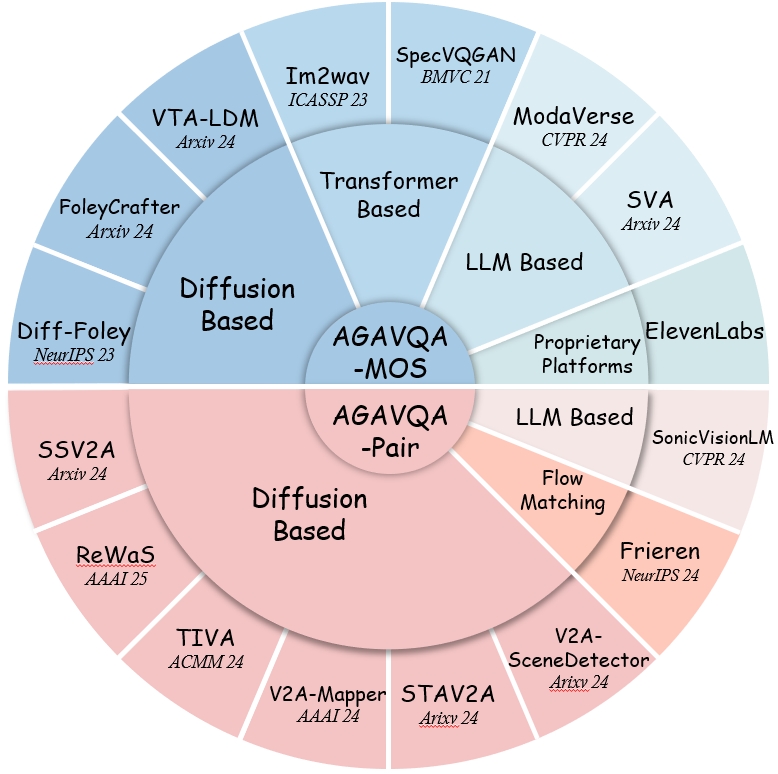
Samples in the AGAVQA-MOS Subset
Audio Quality: 81.33
Audio-visual Content Consistency: 75.47
Overall Audio-visual Quality: 81.22
Audio Quality: 73.31
Audio-visual Content Consistency: 59.18
Overall Audio-visual Quality: 69.78
Audio Quality: 56.59
Audio-visual Content Consistency: 53.38
Overall Audio-visual Quality: 62.00
Audio Quality: 73.03
Audio-visual Content Consistency: 56.54
Overall Audio-visual Quality: 55.78
Audio Quality: 56.83
Audio-visual Content Consistency: 65.74
Overall Audio-visual Quality: 52.20
Audio Quality: 34.85
Audio-visual Content Consistency: 34.20
Overall Audio-visual Quality: 35.73